
This article by Simon Martinelli first appeared in German in the JavaSpektrum Magazine 05/2019
For several years, the microservices architecture has established itself as a quasi-standard and is deployed in many projects. That it is not a catch-all solution is well known. But how do microservices influence the lifecycle of an application, and which paradigms are important for other styles of architecture?
This article explores key characteristics of microservices architecture, including modular design, communication styles, and trade-offs compared to monoliths.
Modularisation
Modularisation is one of the most important concepts of software development. A module forms a self-contained component of a system, which becomes exchangeable due to well-defined internal and external interfaces. A module’s internal bindings and the couplings between modules define the structure of a system. The bindings are a qualitative measure of a module’s compactness. The relationships between a module’s elements are of significance, and these should be as distinctive as possible.
The modules in a good architecture all possess very strong bindings. The modules’ couplings are a qualitative measure of the interfaces between them. Important characteristics are the coupling mechanism, the interface width, and the nature of the communication. Low coupling between modules enables each module to be developed and operated independently. Moreover, loosely connected modules are easier to exchange, simplifying maintenance and further development.
The Right Cut: Defining Microservice Boundaries
The most important and simultaneously most difficult task when defining an architecture is breaking down the system into modules. David L. Parnas already covered the importance of the criteria according to which modules are formed in his 1971 article “On the criteria to be used in decomposing systems into modules” [Par71]. Where breaking down into modules is concerned, we nowadays refer to the concept of bounded contexts from Eric Evans’ Domain-Driven Design [DDD]. Bounded contexts separate the domain into subdomains, in which a defined model is valid.
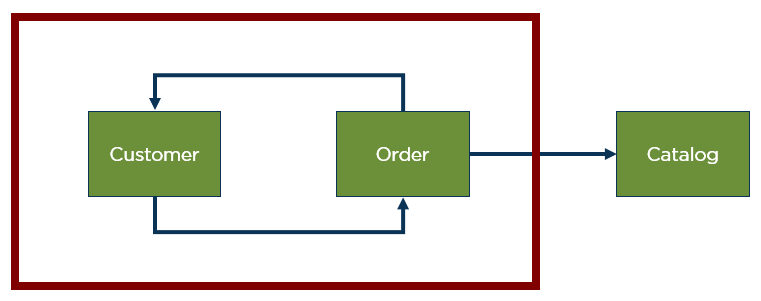
An example that is often used to illustrate modular architectures is the online shop. Usually, there are three modules, as illustrated in figure 1: Customer, order, and a catalog of products. Unfortunately, there is already a strong relationship between the two modules in this small example: Customer and order call each other. This leads to a cycle. Cycles should be avoided, as they generate a high coupling, resulting in both modules only being modifiable at the same time. It also remains unclear if the modules have been correctly defined or if combining them into a single module wouldn’t be better.
When breaking down into modules, the question of how large the ideal module is should also arise. The “micro” in microservice architectures suggests that modules should be as small as possible. The size does not seem decisive if we follow the bounded contexts principle. An example: A B2C webshop requires only a few entities to describe its customers, such as customer name, delivery address, and payment information. In the B2B case, a customer is described by a dozen entities. But in both cases, we are looking at the customer module.
Big Ball of Mud vs. Microservices: Modularity Matters Most
The opposite of modular software architecture is described as “a big ball of mud”. A “big ball of mud” describes a system that has grown over time without awareness of software architecture, which shows no discernible structure. Such systems are difficult to maintain and can often only be replaced whole, creating very high costs during further development.
How can one thus avoid a “big ball of mud”? One has to define and communicate a target architecture. To this end, the modules are defined. Developing a pattern language also helps. This will help all involved to communicate better. According to my experiences in software modernization projects, the correct assignment of responsibilities is very important. Particularly the infrastructure code should be separated from the technical code.
Validating the architecture is another important aspect. The code base must be verified against the target architecture as soon as the first line of code is written. Tools such as Structure101, Sonargraph, ArchUnit, jqAssistant, etc., help to visualize and check the dependencies. As microservices architectures feature distributed dependencies, one should value interface management and reflect on whether the relationships are correct and necessary.
SOA vs. Microservices: Distribution is a Difference
Microservices architectures are often denoted as SOA 2.0. The hype surrounding service-oriented architecture [SOA] already began in the mid-nineties. SOA, as well as microservices, are a style of architecture. In SOA, the service can be described as follows: “ A service is a logical representation of repeatable business activity with a certain result (e.g., checking the creditworthiness of a customer, querying weather data). A service is self-contained and can consist of other services. The service represents a BlackBox for its user.”
The big difference between microservices is that SOA makes no statement concerning distribution. The SOA services of applications are often offered as interfaces. Due to the definition of SOA, the term service can be compared to serverless architectures’ functions.
Microservices vs. Monolith
The opposite of a microservices architecture is the monolith. Microservice-based and monolithic architectures differ in particular regarding distribution. Distributed systems do not just have advantages but also bring in problems concerning network communication. For example, services can malfunction or exhibit long response times. Concepts such as circuit breaking, caching, and redundancies come into play, increasing complexity. In his article [Fow03], Martin Fowler wrote: “First Law of Distributed Object Design: Don’t distribute your objects!”
To distribute and scale modules independently, these must be distributed. In this case, a synchronous communication style via RESTH/TTP is often chosen. This can lead to the O/R-mapper’s dreaded n+1 select problem shifting to the communication layer between microservices.
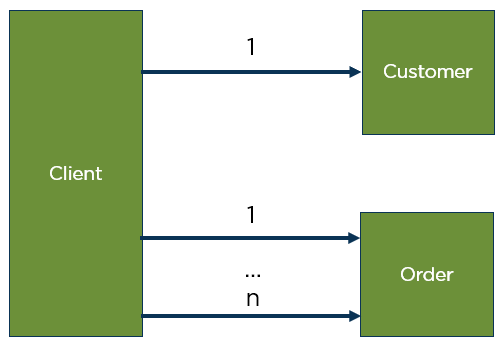
Figure 2 shows a client trying to query all orders of a group of customers. A naive approach would see an initial query with the customer service to obtain the list of customers before querying each customer’s orders separately. It is unavoidable that this kind of communication will lead to performance problems.
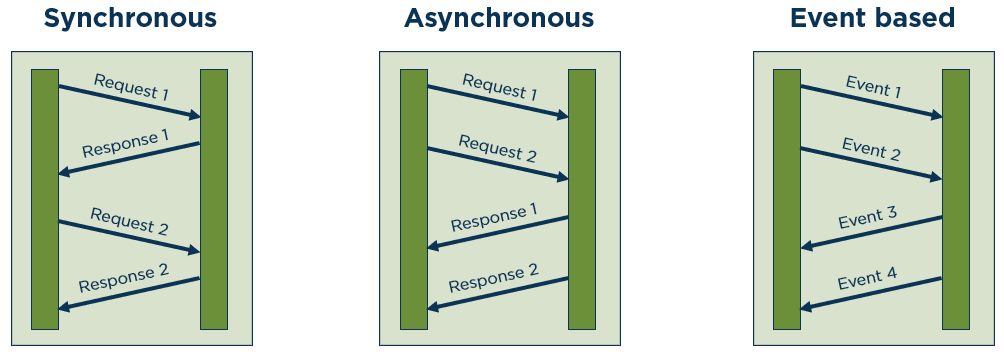
Another very important aspect of distributed communication is the communication style involved. Figure 3 shows that, besides synchronous communication styles, there are also asynchronous communication styles, which lead to better decoupling. Synchronous communication can be simulated using the request/reply model. The question, however, is how long should we wait for an answer, and what should we do if the answer doesn’t come? One possibility would be to repeat the query. However, if the service is not implemented idempotent, the query could be processed twice.
The event-driven communication model offers the greatest possible decoupling. This model support loose coupling between services. A large advantage is that the sender does not need to know in which state the recipient is, who the recipient is, or how the event is processed (if at all). The responsibility on the querying side is eliminated, as one does not need to wait for an answer. Another advantage of event-based systems is that any number of services can consume the events, thus allowing for data replication.
Distributed Big Ball of Mud
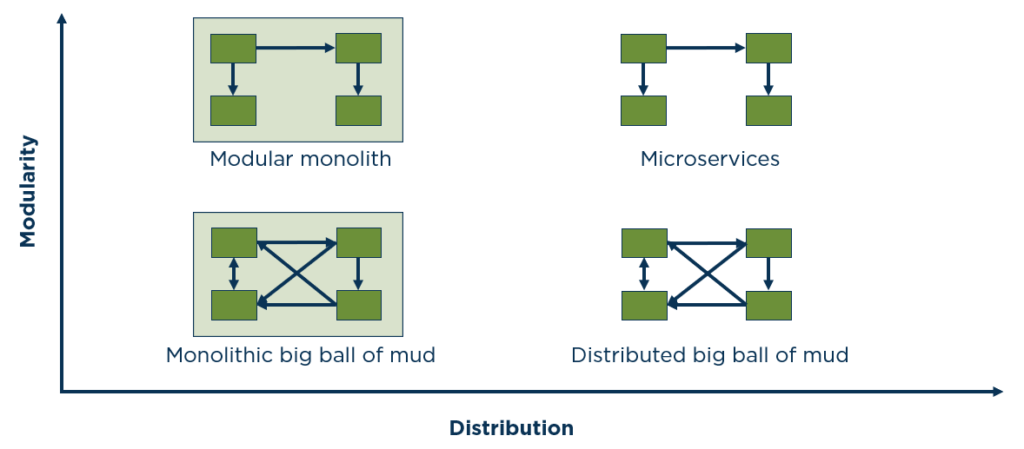
In figure 4, the x-axis indicates the degree of distribution, and the y-axis indicates the modularity. The figure nicely illustrates that separating into preferably independent modules is the most important criterium for good architecture. Whether these modules are then distributed or not is only affected by the requirements for exchangeability and independent scaling. However, if we abstain from modularity, both architectures will form a “big ball of mud”. In his talk on modular monoliths, held during the DevNexus 2016 conference in Atlanta, Simon Brown aptly said: “If you cannot build a modular monolith, then why do you think that microservices are the solution?”
Unfortunately, a distributed “big ball of mud” is even more unfavorable for maintenance and further development than a monolithic one. A monolithic code base can be analyzed with analysis tools and converted. However, with a distributed “big ball of mud”, the runtime needs to be analyzed to determine which modules communicate with one another. Verifying whether the architectural and design specifications are being met is thus important in any architecture.
Characteristics
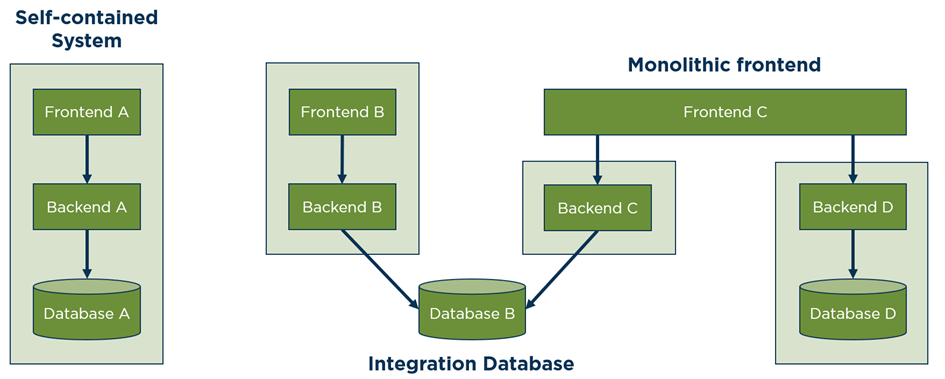
In the past, microservices architectures were mostly present in the backend, which led to the formation of so-called frontend monoliths. This nullified one advantage, namely that of independence. The idea of self-contained systems (SCS), modules that contain all layers, is one variant to solve this problem. On the other hand, it is a principle in microservices architectures that each microservice has its own data management. However, in modernization projects, the data management method that Fowler describes as an “integration database” is often the only possibility to break down the monolith, as the existing data models are heavily normalized, and the tables have many dependencies (see fig. 5).
Furthermore, other systems, such as a data warehouse, often use the data model, complicating the decomposition. Converting a monolith into microservices often follows the “strangler” pattern. After his trip to Australia, Martin Fowler first described this design pattern in 2004 [Fow04]. The system to be converted is successively embraced by new modules, as by a strangler fig, until nothing remains of the old system. The risk, as compared to a big-bang migration, is much smaller.
Conclusion
Modularisation, the most important aspect of software architecture, has returned to the foreground, thanks to the many discussions about microservices. Correctly implemented, a microservices architecture will lead to better modularisation. The developers can better follow a predetermined target architecture, as it is more difficult to query a distant service than to instantiate a class. A microservices architecture also positively affects future migrations, as the independently distributed modules are easier to replace. It is important to know why one is choosing a microservices architecture and whether one wants to pay the price of the distribution. One should never repeat mistakes from the past and produce a microservice-based “big ball of mud”.
Links
[Parnas] David L. Parnas: On the criteria to be used in decomposing systems into modules, 1971, https://kilthub.cmu.edu/articles/On_the_criteria_to_be_used_in_decomposing_systems_into_modules/6607958
[DDD] Eric Evans: Domain-Driven Design. Tackling Complexity in the Heart of Software. Addison-Wesley, 2003, ISBN 978-0-321-12521-7
[SOA] Service Oriented Architecture, http://www.opengroup.org/soa/source-book/soa/index.htm
[FOWLER] Martin Fowler, Errant Architectures, 2003, http://www.drdobbs.com/errant-architectures/184414966
[SCS] Self-Contained Systems, https://scs-architecture.org/
[Strangler] Martin Fowler, 2004, https://martinfowler.com/bliki/StranglerFigApplication.html
